


Building a Working Recommendation Engine from Scratch
An Image Feed Curated by an Algorithm

Most examples of recommendation algorithms on the internet remain very theoretical and mathematical, rarely showing the problems encountered in real-life implementation. Additionally, they often base their recommendations on user ratings. I want to attempt to program a recommendation engine from scratch that serves as a source of inspiration, recommending content such as images, videos, or links. I will avoid using machine learning algorithms entirely to ensure that my algorithm's recommendations are always understandable.
For data, I will use the online platform Are.na, where users can publish and collect various types of content. Some might say Are.na is the artsy version of Pinterest or Tumblr.
Are.na is suitable for this attempt for several reasons:
It provides a public API.
Content is grouped into channels, creating thematic islands.
It currently lacks its own recommendation algorithm.
How Are.na Works
Users create channels and add blocks (aka posts) to them. A block can be an image, text, link, or even another channel. Blocks can be added individually or connected from other channels. This creates groupings of blocks that users perceive as related.
Hypothesis
The number of overlaps in connected blocks between channels or users can indicate relevance i.e. how relevant another channel or user is to me. The more blocks my channels share with another user's channels, the higher the probability that the blocks we don't yet share will also interest me.
Tech Stack
“The best stack is the one you know best”, so I've chosen TypeScript and a Node.js Express server. To keep the project small initially, I've decided against a database and will store data in local JSON files.
Mini Proof of Concept
Let's start with a small proof of concept to validate the thesis and check the quality of the recommendations.
To get my first recommendation, I took all the blocks from a channel and noted the channels to which each block is connected. If a channel appeared in multiple blocks, I incremented a counter.
The result is a list of all channels wich contain blocks also present in our channel. Sorting this list by frequency places channels with the most overlaps at the top.
[
{
"slug": "the-palm-report-by-poolsuite",
"overlappingBlocks": 24
},
{
"slug": "swipes-bieszxtppxw",
"overlappingBlocks": 22
},
{
"slug": "beautiful-confusion",
"overlappingBlocks": 21
},
{
"slug": "direction-tnOtfoyhqzo",
"overlappingBlocks": 9
},
{
"slug": "crying-at-nothing-but-colors",
"overlappingBlocks": 5
},
{
"slug": "atmosphere-mdjbcwxlbp4",
"overlappingBlocks": 5
},
{
"slug" : "entdeckungen",
"overlappingBlocks": 4
}
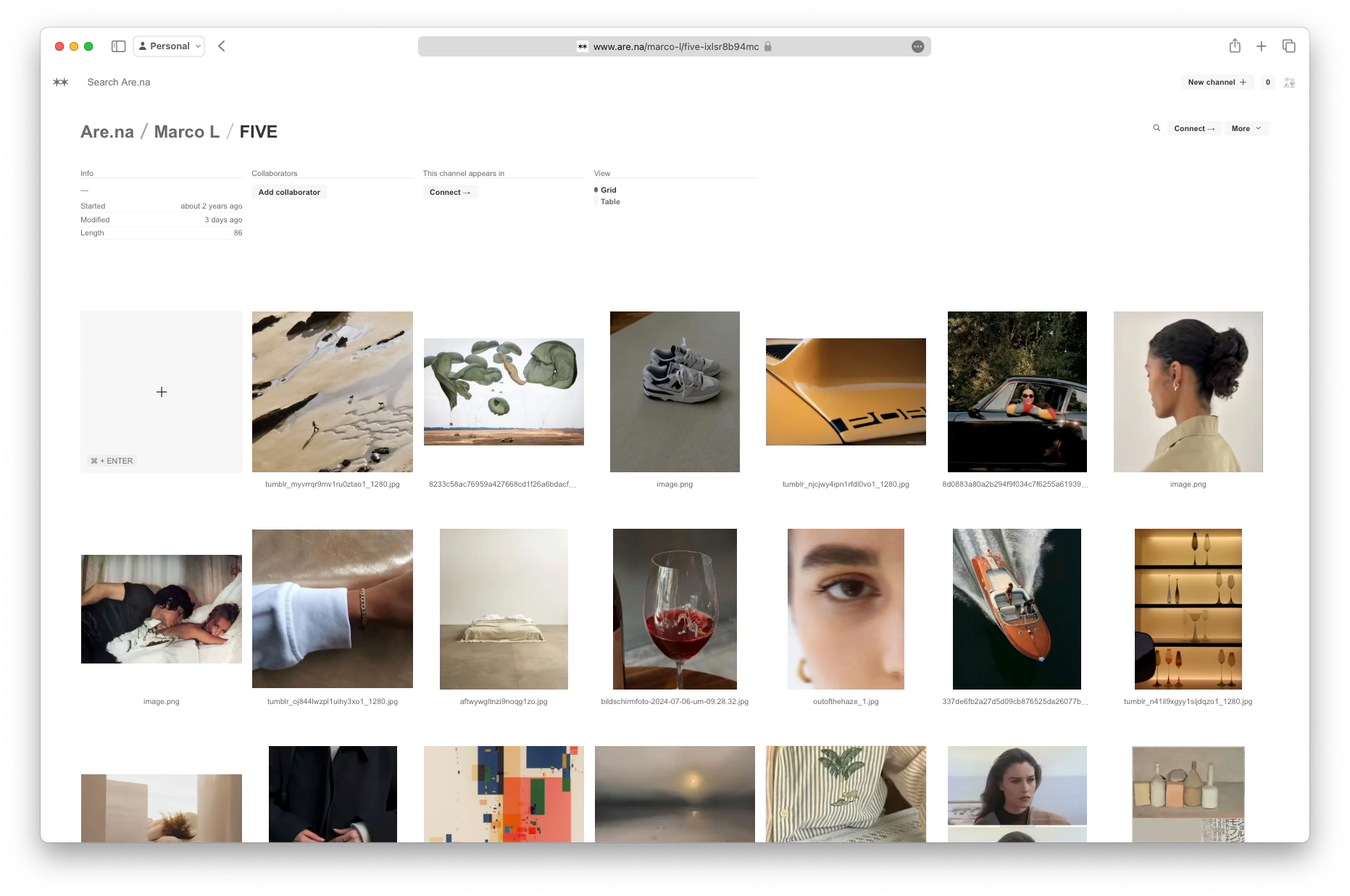
]A quick look at the top three channels confirms that they deal with similar content and aesthetically align with the original channel.



Learnings
Filtering Information
The recommended channels often include the user's own channel and those they already follow. While it's true that these channels likely appeal to the user, they aren't relevant for recommendations. We'll need to systematically exclude certain channels from recommendations.
Are.na's API
To fetch the connected channels of each block, I wanted to use Are.na’s /v2/channels/:id/connections API endpoint. Unfortunately, this doesn't return the connected channels as documented. This made development more time-consuming because instead of a single request, I now need one request per blocks in the channel plus one initial request for the list of blocks.
Caching
Due to the many individual requests needed to analyze a channel, I will have to implement server response caching next. Currently, it takes the server over 5 minutes to analyze a channel with 80 blocks. I suspect this is partly due to Are.na's API throttling requests.
Implementing Caching
Typically, for caching, you would install a fast database to temporarily store information that would otherwise be fetched from Are.na's servers. To keep it simple for now, I decided to store Are.na's responses in JSON files.
Implementing this was relatively easy: I created a getData function that checks if data for a URL is already in the cache before making a request. If so, it returns the cached data. If not, it fetches and caches the data for future use.
async function getData(url: string) {
const fileName = url.replace(/[^a-zA-Z0-9]/g, '_');
const filePath = `/cache/${fileName}.json`;
if (fs.existsSync(filePath)) {
const cacheData = fs.readFileSync(filePath, 'utf8');
return JSON.parse(cacheData);
}
const data = await fetch(url).then((res) => res.json());
fs.writeFileSync(filePath, JSON.stringify(data));
return data;
}For now, this method works well, as it reduces load times to under 10ms, allowing me to see results without waiting 5 minutes between code adjustments. Additionally, the cache is granular enough to be efficiently reused. For example, if I fetch Channel 1 and cache the information for each block, the cache can be used when fetching Channel 2 if it contains some of the same blocks.
However, this approach has unresolved issues, the biggest being the lack of invalidation. Once a URL is cached, it’s used indefinitely, ignoring changes made to the channel. For now, I'm okay with manually clearing the cache occasionally.
First Attempt at Creating a Feed Algorithm
We now have all the components to build a feed from the collected data. We can recommend other channels based on a starting channel, fetch blocks from those channels, and display them to the user in a feed.
The strategy for this algorithm is:
Find channel recommendations based on a starting channel.
Sort them by overlap (number of shared blocks).
Take the top 10 channels from this list.
Take the 10 newest blocks from each of these 10 channels.
This gives us a list of 100 blocks that are all potentially relevant and can be displayed as a feed. I'm filtering out all blocks that aren't images, as I find it easier to validate the algorithm's quality by reviewing a gallery of images.

In the feed, blocks are sorted by updated_at, showing recently connected blocks at the top.
Of course, the feed does not consist of 100% matching images, but there is still a good number of overlapping themes: still life, portraits, and generally brighter and calmer images. It definitely doesn't look like this channel suggested by Are.na's Explore feed, so that’s already an improvement.

Improving the Algorithm
While the algorithm achieves a good hit rate for some blocks, there are also irrelevant blocks. I believe there's a relatively simple way to improve quality.
Looking at the top suggested channels, the number of overlapping blocks is unevenly distributed. The top 3 channels have significantly more overlap than the others. We can assume these are more relevant and should display more blocks from these channels.

To implement this, each channel receives a weight determining how many blocks to fetch from it. This results in more blocks from the top channels and fewer from the lower ones. I’m initially pleased with this result as I see many images similar to those in my channel, but also some atypical ones, adding diversity to the feed.
[
{
"slug": "the-palm-report-by-poolsuite",
"overlappingBlocks": 24,
"weight": 0.2666666667
},
{
"slug": "swipes-bieszxtppxw",
"overlappingBlocks": 22,
"weight": 0.2444444444
},
{
"slug": "beautiful-confusion",
"overlappingBlocks": 21,
"weight": 0.2333333333
},
{
"slug": "direction-tnOtfoyhqzo",
"overlappingBlocks": 9,
"weight": 0.1
},
{
"slug": "crying-at-nothing-but-colors",
"overlappingBlocks": 5,
"weight": 0.0555555556
},
{
"slug": "atmosphere-mdjbcwxlbp4",
"overlappingBlocks": 5,
"weight": 0.0555555556
},
{
"slug" : "entdeckungen",
"overlappingBlocks": 4,
"weight": 0.0444444444
}
]The feed created with the improved algorithm:

Learnings
It’s clear that blocks already known to me or already in my channel disrupt the feed. We definitely need a solution to filter out these blocks.
Another problem with the current approach, is that blocks from inactive channels remain part of the feed for a long time, while blocks from very active channels may not be displayed, even if they are more relevant to the user.
I believe this issue can be resolved by preparing and updating the feed continuously through automated processes instead of creating it on request. This is new territory for me, so I will first look at existing solutions.
Conclusion
Of course, we are still far from having a sophisticated and production-ready algorithm, but we've made a good start and were able to show users new, relevant content. The thesis that channels contain related blocks has been confirmed. It’s also a promising approach to use channels with high content overlap as sources for recommendations.
As the pool of content we select from grows (more channels), more irrelevant content mixes in. Irrelevant content must be quickly identified as such to prevent further recommendations.
Generating recommendations on “request-time” works for the prototype through caching, but it's just a workaround. We can't continue this approach in a production environment: Initial caching takes several minutes, caches occupy considerable storage, and they must be renewed regularly. Recommendations should be created regularly and automatically so that they are available at “request-time”. I envision a routine that regularly creates a feed of suggestions and stores it in a database.
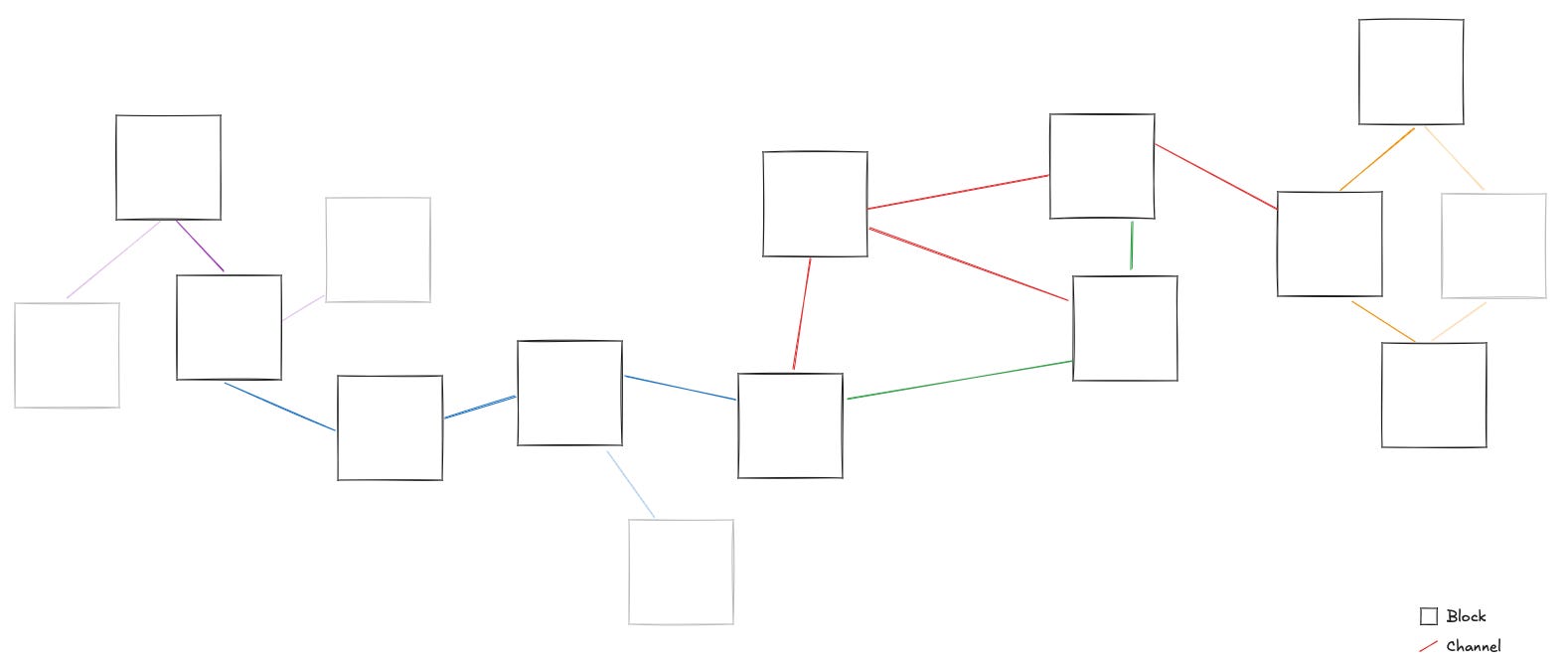
If we think of Are.na as a network where each block is connected to one or more other blocks through channels, the current algorithm only suggests blocks from the surrounding neighborhood. This results in a high hit rate, but may miss interesting blocks located elsewhere in the network.
I can imagine that the algorithm would provide more diverse content if it also considers channels that are farther away in the network.

Next Steps
From the above insights, several tasks have emerged that I would like to implement:
Blocks the user already knows should not be recommended.
Blocks from followed channels should probably always be shown.
Recommendations should be created regularly and automatically so that they exist at the time of request.
The algorithm’s horizon should be expanded.
Currently, our recommendations are based on a single channel. Since users' interests are usually spread across multiple channels, they should all be considered.
The quality of recommendations is currently assessed by me personally by reviewing the results. It would be more sensible to measure the quality programmatically to compare different versions of the algorithm. I hope to find literature on this.